Code Migration to the Cerebras Architecture¶
From the Cerebras documentation How Cerebras Works, the main idea for getting to run on the Neocortex system using the Cerebras machines, is to first port the code from using regular TensorFlow or PyTorch code, to use the Cerebras libraries.
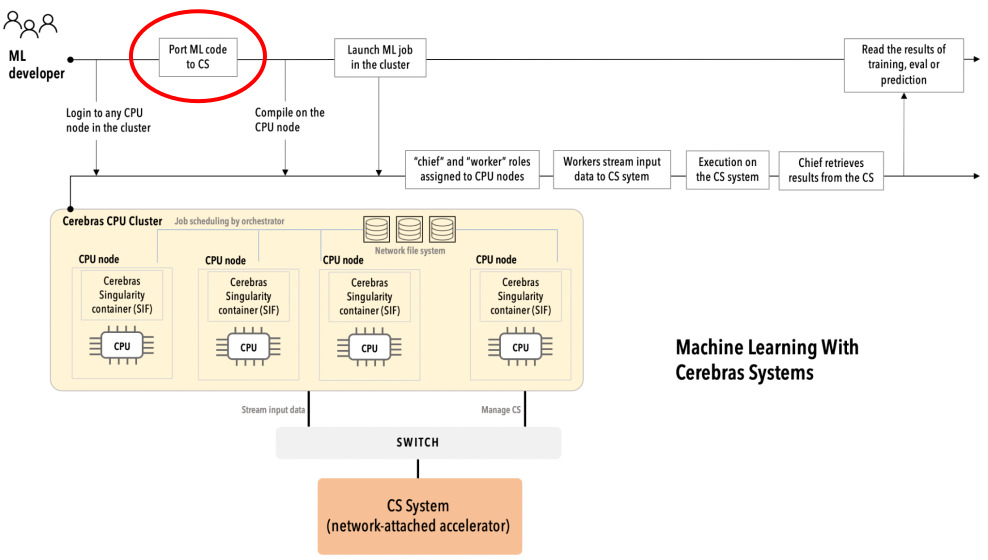
Then, in the Workflow for TensorFlow on CS documentation page, the steps listed are as follows and go over the process needed for performing such code migration. This is a good starting point for understanding the process
- Port to Cerebras
- Prepare input
- Compile on CPU
- Run on Cerebras
Note
An estimation of the required effort to get the code ready is one to four weeks for a single person performing all of the edits.
For track one users: For “1. Port to Cerebras,” you will only need to follow the sections related to input function or dataloader. You will not need to modify the model or the overall code structure.
TensorFlow¶
In more detail, the steps needed for porting an existing TensorFlow codebase to run on Neocortex are:
- Modify
model_fn()inmodel.pyto build the layers of your model function, return atf.estimator.EstimatorSpecobject - Modify
input_fn()indata.py, return atf.data.Dataset object - Implement custom helper logic in
utils.py, as needed - Set dataset path and model parameters in
configs/params.yaml - Run
run.pyto validate and compile your code
The following diagram shows the suggested order in which the modifications should be performed for porting the code. The arrows represent the suggested order for the modification process to perform. This diagram should be read from left to right.

The following diagram uses arrows to represent the logical flow of information and arguments passed when running the code. This diagram should be read from left to right and from top to bottom.

Structure of the code¶
Examples can be found in the cerebras_reference_implementation repository, which contains examples of standard deep learning models that can be trained on Cerebras hardware and demonstrate the best practices for coding
model.py: It contains the model function definition. For information about the layers supported, please visit the Cerebras Documentation.data.py: where the input data pipeline is called. Additional data processor modules may be defined elsewhere (e.g., in theinputfolder) for data pipeline implementation.utils.py: it contains the helper scripts.configs/params.yaml: YAML file containing the model configuration and the training hyperparameter settings.run.py: it contains the training/compilation/evaluation script.
Info
Suggested order of files to use: model.py -> data.py -> utils.py -> configs/params.yaml -> run.py
model.py¶
The model function that defines your neural network model. Contains the model function definition and model implementation.
It supports the usage of the Tensorflow Keras Layers API, but the Tensorflow Metrics API is not supported.
These files get things ready for the Estimator API. The code is divided between what is run in the host (I/O functions, support server, SDF), and what will run in the wafer.
Note
Please have in mind your code will not call "train" nor "fit" as the Estimator does that (takes care of that responsibility).
For information about the layers supported, please visit the Cerebras Documentation.
def model_fn(features, labels, mode, params) -> tf.estimator.EstimatorSpec/common.tf.estimator.cs_estimator_spec.CSEstimatorSpec:
Input:
- These input arguments (features, labels) are taken automatically from the values returned from the input_fn method, the run configuration set by run.py (mode) and the
configs/params.yamlfile. -
features: This is the first item returned from theinput_fn. It should be a singletf.Tensorordict. -
labels: This is the second item returned from theinput_fn. It should be a singletf.Tensorordict. If mode istf.estimator.ModeKeys.PREDICT,labels=Nonewill be passed. -
mode: it specifies if this is running in training, evaluation, or prediction mode. -
params: additional configuration as adictof hyperparameters loaded from the configs/params.yaml file to configure Estimators for tuning
-
tf.estimator.EstimatorSpec: it fully defines the model to be run by an estimator.
The EstimatorSpec takes:
mode: passed automatically from the parent model_fn function.loss: model losstrain_op: optimizerhost_call(dict):
data.py¶
Input data pipeline implementation: the input pipeline must be very fast, you must ensure you preprocess the input data by sharding, shuffling, prefetching, interleaving, repeating, batching, etc., in proper order.
The input function builds the input pipeline and yields the batched data in the form of (features, labels) pairs, where:
featurescan be a tensor or dictionary of tensors, andlabelscan be a tensor, a dictionary of tensors, or None.
Inputs
- params (
dict):
{
train_input: dict = {
data_dir: str,
num_parallel_calls: int = 0,
train_batch_size: int, eval_batch_size: int, batch_size: int,
shuffle: bool
}
}
mode(str): One of thetf.estimator.ModeKeys.*string. The available options are:TRAIN,EVAL,TRAIN_AND_EVAL, andINFERENCE
Output
tf.data.Dataset: "features" and "labels" will be inside this Dataset object as the handles to the batched data that the model will use.
utils.py¶
It contains the helper scripts, including get_params which parses the params dictionary from the YAML file. You can also include the user-defined helper functions here or elsewhere.
configs/¶
Directory of YAML files containing model configurations and training hyperparameters (params.yaml).
If you would like to utilize the models in the examples directly but just change a few settings such as the number of layers, dimension, and hyperparameters, the easiest way is to change parameter values in a YAML config file. The parameter values will be read when the program starts and passed to the code function as a dictionary.
A few examples of contents in the params.yaml file:
- train_input:
data_dir:'./tfds'# Place to store databatch_size:256
- model:
activation_fn:'relu'# Other options: relu, tanh, elu, selu, linear (identity)
- optimizer:
learning_rate:0.001
- runconfig:
max_steps:100000save_checkpoints_steps:10000keep_checkpoint_max:2model_dir:'model_dir'
For more details regarding the parameter files and arguments that can be specified, please refer to the Pytorch Create Params YAML file Cerebras Documentation page.
run.py¶
It contains the training script, performs train and eval. This file contains the general framework to build the estimator and most of the time it should not be modified.
For more information please visit the Porting TensorFlow to Cerebras Cerebras documentation page.
PyTorch¶
This is an overview of the steps needed for porting an existing PyTorch codebase to run on Neocortex:
- Modify the data loaders for training (
get_train_dataloader) and evaluation (get_eval_dataloader) indata.py, return atorch.utils.data.DataLoaderobject - Modify
model.pyto define the model using aPyTorchBaseModelclass. - Modify
configs/params.yamlto set the dataset path and model definition parameters. - Modify
run.pyto validate and compile your code.
The following diagram shows the suggested order in which the modifications should be performed for porting the code. The arrows represent the suggested order for the modification process to perform. This diagram should be read from left to right.

The following diagram uses arrows to represent the logical flow of information and arguments passed when running the code. This diagram should be read from top to bottom.

Structure of the code¶
Examples can be found in the cerebras_reference_implementation repository, which contains examples of standard deep learning models that can be trained on Cerebras hardware and demonstrate the best practices for coding
model.py: It contains the model function definition.data.py: where the input data dataloaders are defined.utils.py: it contains the helper scripts.configs/params.yaml: YAML file containing the model configuration and the training hyperparameter settings.run.py: it contains the training/compilation/evaluation script.
Info
Suggested order of files to use: model.py -> data.py -> utils.py -> configs/params.yaml -> run.py
model.py¶
The model definition for the model. Contains the model definition and model implementation.
The goal is to define a torch.nn.Module class and use it as input for a PyTorchBaseModel class, that will later be used as input for the run()`` method inrun.py` (more details down below in this same document).
class Model(torch.nn.Module):
def __init__(self, params):
...
def forward(inputs):
...
return outputs
...
class BaseModel(PyTorchBaseModel):
def __init__(self, params, device = None)
self.model = Model(params) # Use the Model class defined above.
self.loss_fn = ...
...
super().__init__(params=params, model=self.model, device=device)
def __call__(self, data):
...
inputs, targets = data
outputs = self.model(inputs)
loss = self.loss_fn(outputs, targets)
return loss
data.py¶
Input data pipeline implementation: the input pipeline must be very fast, you must ensure you preprocess the input data by sharding, shuffling, prefetching, interleaving, repeating, batching, etc., in proper order.
def get_train_dataloader(params):
...
loader = torch.utils.data.DataLoader(...)
return loader
def get_eval_dataloader(params):
...
loader = torch.utils.data.DataLoader(...)
return loader
Inputs
- params: (dict)
Output
torch.utils.data.DataLoader: This object takes a torch.utils.data.TensorDataset object with the images and labels to use, as well as the batch_size, shuffle, and any other arguments defined in the params file.
utils.py¶
It contains the helper scripts, including get_params which parses the params dictionary from the YAML file. You can also include the user-defined helper functions here or elsewhere.
configs/¶
Directory of YAML files containing model configurations and training hyperparameters (params.yaml).
If you would like to utilize the models in the examples directly but just change a few settings such as the number of layers, dimension, and hyperparameters, the easiest way is to change parameter values in a YAML config file. The parameter values will be read when the program starts and passed to the code function as a dictionary.
The main information to be defined in the config files is:
- The optimizer defines learning rates and optimizer details. (required)
- The model section defines architecture hyperparameters. (optional)
A few examples of contents in the params.yaml:
- train_input:
data_dir:'./tfds'# Place to store databatch_size:256
- model:
mixed_precision:boolinput_size:int
- optimizer:
learning_rate:0.001
- runconfig:
max_steps:100000checkpoints_steps:2000
run.py¶
It contains the training script, performs train and eval. This file contains the general framework to build the estimator and most of the time it should not be modified.
An example invocation looks like this:
run(model_fn=MNISTModel,
train_data_fn=get_train_dataloader,
eval_data_fn=get_eval_dataloader,
default_params_fn=set_defaults)
model_fn: Required. A callable that takes in a dictionary of parameters. Returns aPyTorchBaseModel.train_data_fn: Required during training run.eval_data_fn: Required during evaluation run.default_params_fn: Optional. A callable that takes in a dictionary of parameters. Sets default parameters.
For more information please visit the Porting PyTorch Model to CS Cerebras documentation page.